书接上回,在 记一个 Base64 有关的 Bug 一文里,我们说到了 Base64 的编解码器有不同实现,交叉使用它们可能引发的问题等等。
这一回,我们来对 Base64 这一常用编解码技术的原理一探究竟。
1. Base64 是什么
Base64 是一种基于 64 个可打印字符来表示二进制数据的表示方法。由于 2^6=64,所以每 6 个比特为一个单元,对应某个可打印字符。3 个字节有 24 个比特,对应于 4 个 Base64 单元,即 3 个字节可由 4 个可打印字符来表示。
——维基百科
它不是一种加解密技术,是一种简单的编解码技术。
Base64 常用于表示、传输、存储二进制数据,也可以用于将一些含有特殊字符的文本内容编码,以便传输。
比如:
在电子邮件的传输中,Base64 可以用来将 binary 的字节序列,比如附件,编码成 ASCII 字节序列;
将一些体积不大的图片 Base64 编码后,直接内嵌到网页源码里;
将要传递给 HTTP 请求的参数做简单的转换,降低肉眼可读性;
注:用于 URL 的 Base64 非标准 Base64,是一种变种。
网友们在论坛等公开场合习惯将邮箱地址 Base64 后再发出来,防止被爬虫抓取后发送垃圾邮件。
2. Base64 编码原理
标准 Base64 里的 64 个可打印字符是 A-Za-z0-9+/,分别依次对应索引值 0-63。索引表如下:
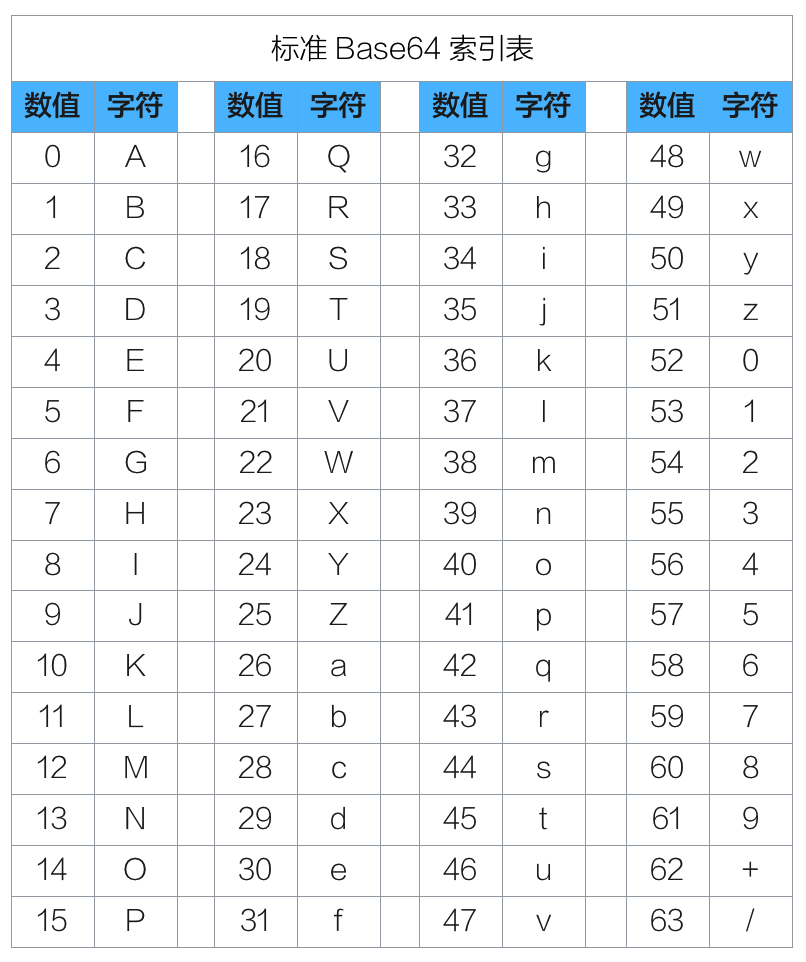
编码时,每 3 个字节一组,共 8bit*3=24bit,划分成 4 组,即每 6bit 代表一个编码后的索引值,划分如下图所示:

这样可能不太直观,举个例子就容易理解了。比如我们对 cat 进行编码:

可以看到 cat 编码后变成了 Y2F0。
如果待编码内容的字节数不是 3 的整数倍,那需要进行一些额外的处理。
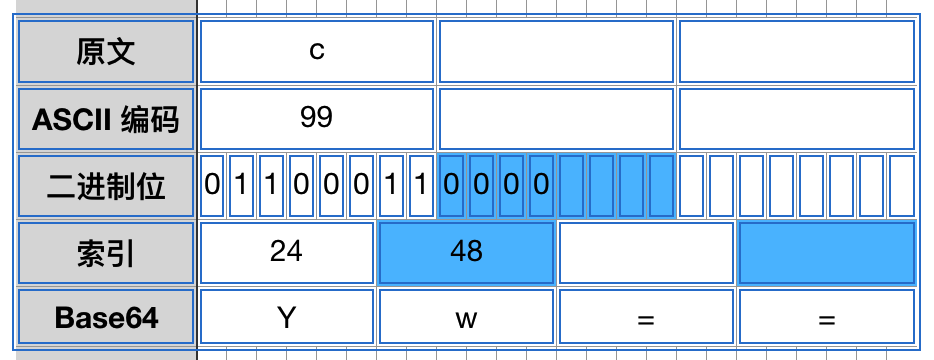
如果最后剩下 1 个字节,那么将补 4 个 0 位,编码成 2 个 Base64 字符,然后补两个 =:
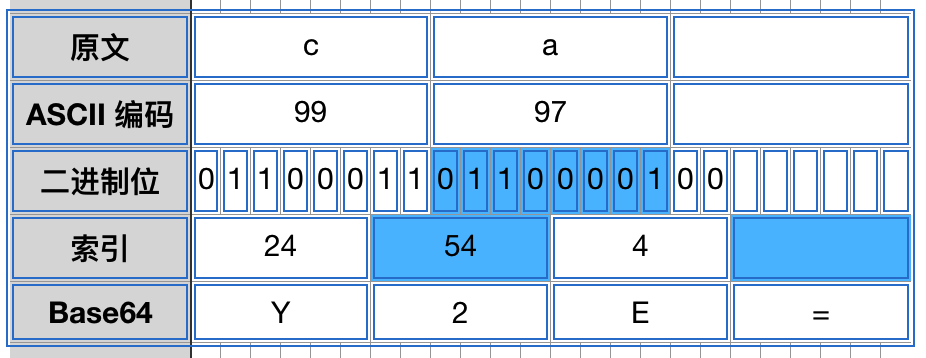
如果最后剩下 2 个字节,那么将补 2 个 0 位,编码成 3 个 Base64 字符,然后补一个 =:
3. 实现一个简易的 Base64 编码器
讲完原理,我们就可以动手实现一个简易的标准 Base64 编码器了,以下是我参考 Java 8 的 java.util.Base64 乱写的一个 Java 版本,仅供参考,主要功能代码如下:
public class CustomBase64Encoder {
/**
* 索引表
*/
private static final char[] sBase64 = {
'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H',
'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P',
'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X',
'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f',
'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n',
'o', 'p', 'q', 'r', 's', 't', 'u', 'v',
'w', 'x', 'y', 'z', '0', '1', '2', '3',
'4', '5', '6', '7', '8', '9', '+', '/'
};
/**
* 将 byte[] 进行 Base64 编码并返回字符串
* @param src 原文
* @return 编码后的字符串
*/
public static String encode(byte[] src) {
if (src == null) {
return null;
}
byte[] dst = new byte[(src.length + 2) / 3 * 4];
int index = 0;
// 每次将 3 个字节编码为 4 个字节
for (int i = 0; i < (src.length / 3 * 3); i += 3) {
int bits = (src[i] & 0xff) << 16 | (src[i + 1] & 0xff) << 8 | (src[i + 2] & 0xff);
dst[index++] = (byte) sBase64[(bits >>> 18) & 0x3f];
dst[index++] = (byte) sBase64[(bits >>> 12) & 0x3f];
dst[index++] = (byte) sBase64[(bits >>> 6) & 0x3f];
dst[index++] = (byte) sBase64[bits & 0x3f];
}
// 处理剩下的 1 个或 2 个字节
if (src.length % 3 == 1) {
int bits = (src[src.length - 1] & 0xff) << 4;
dst[index++] = (byte) sBase64[(bits >>> 6) & 0x3f];
dst[index++] = (byte) sBase64[bits & 0x3f];
dst[index++] = '=';
dst[index] = '=';
} else if (src.length % 3 == 2) {
int bits = (src[src.length - 2] & 0xff) << 10 | (src[src.length - 1] & 0xff) << 2;
dst[index++] = (byte) sBase64[(bits >>> 12) & 0x3f];
dst[index++] = (byte) sBase64[(bits >>> 6) & 0x3f];
dst[index++] = (byte) sBase64[bits & 0x3f];
dst[index] = '=';
}
return new String(dst);
}
}
这部分源码我也上传到 GitHub 仓库 https://github.com/mzlogin/spring-practices 的 base64test 工程里了。
4. 其它知识点
4.1 为什么有的编码结果带回车
在电子邮件中,根据 RFC 822 规定,每 76 个字符需要加上一个回车换行,所以有些编码器实现,比如 sun.misc.BASE64Encoder.encode,是带回车的,还有 java.util.Base64.Encoder.RFC2045,是带回车换行的,每行 76 个字符。
4.2 Base64 的变种
除了标准 Base64 之外,还有一些其它的 Base64 变种。
比如在 URL 的应用场景中,因为标准 Base64 索引表中的 / 和 + 会被 URLEncoder 转义成 %XX 形式,但 % 是 SQL 中的通配符,直接用于数据库操作会有问题。此时可以采用 URL Safe 的编码器,索引表中的 /+ 被换成 -_,比如 java.util.Base64.Encoder.RFC4648_URLSAFE 就是这样的实现。
5. 参考链接
- https://zh.wikipedia.org/zh-hans/Base64
- https://www.liaoxuefeng.com/wiki/897692888725344/949441536192576
我的博客即将同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=guk42yjsce8s
文档信息
- 本文作者:Yige Yan
- 本文链接:https://yyg0725.xyz//2020/03/07/get-an-in-depth-understanding-of-base64/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)